

One of the most common mistakes that can occur while building a Power BI model is a loss of "referential integrity". That's a fancy way of saying that you have a one-to-many relationship with data on your many side that doesn't map up to data on the one side.

If you're not using data sensitivity labels and data protection capabilities across your enterprise, you should really start looking at that. This is an important step in identifying and protecting your most sensitive data.

Adam Saxton walks you through all the upcoming changes to Power BI workspaces.

Chris Webb has an interesting article on using Parameters and Deployment Pipelines to limit the amount of data you are handling inside Power BI Desktop (and, thus, on your local machine). If you are using large models, this will prove very useful.

If you have non-performant direct query models, Brett Powell shows you how to speed them up...and reduce the load on the source server.
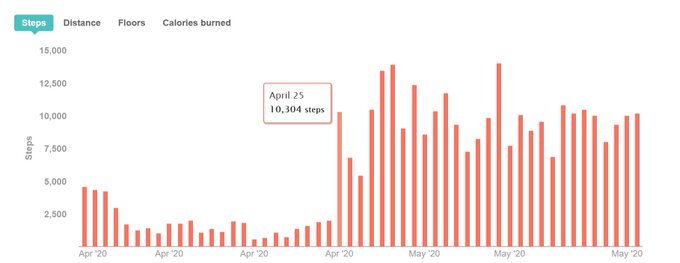
Meagan Longoria has a fun article to remind you that your data visualizations always need to take context into account. Here, she talks about both the data and the important information behind the data.

Every month, Microsoft releases several new features for Power BI. Some are small, and some are game changers. Marc Lelijveld put together a thoughtful strategy for how an organization might phase their roll-out of those new features, so that they can take into account functionality, data governance, etc.

If you ever needed an introduction to Performance Analyzer in Power BI Desktop, Dan Szepesi has a good breakdown.

John White has a kind of ingenious way of creating low-code data-driven subscriptions by combining the Power BI REST API with Power Automate and SharePoint.